
”大数据 MapReduce“ 的搜索结果
大数据Mapreduce实验
标签: 随意
大数据Mapreduce实验
大数据mapreduce案例
标签: s'd'
大数据mapreduce案例介绍,包括代码解释,详解MRS工作流程
需要反射调用空参构造函数,所以必须有空参构造(3)重写序列化和反序列化方法,同时要求顺序一致(4)如果需要将自定义的bean放在key中传输,则还需要实现Comparable接口,因为MapReduce框中的Shuffle过程要求对key...
Hadoop 是一个提供分布式存储和计算的。
大数据技术之 Hadoop(MapReduce) —————————————————————————— 第 1 章 MapReduce 概述 1.1 MapReduce 定义 MapReduce 是一个分布式运算程序的编程框架,是用户开发“基于 ...
本文是从头到尾有关大数据的最完整的文章。
MapReduce 编程模型只包含 Map 和 Reduce 两个过程,map 的主要输入是一对 值,经过 map 计算后输出一对 值;Hadoop 集群常驻进程,根据要处理的输入数据量,命令 TaskTracker生成相应数量的Map和Reduce进程任务,并...
去官网下载Hadoop的安装包,在windows上解压src的也要下载,上面的链接提供了2.6.5的,需要更高版本自行下载下载好压缩包,在windows上解压,并新建一个hadoop-lib的文件夹将下载好的plugin包,放在你的eclipse的...
云计算与大数据 MapReduce实验 Wordcount实验中所需数据包 WordCount.jar 不需要封装,centos7 linux hadoop实验上传所需
大数据mapreduce利用java实现词频统计功能的jar包
Hadoop 是一个提供分布式存储和计算的。
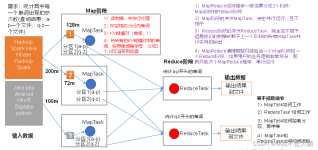
通常在Map Task任务完成MOF输出进度到约3%时启动Reduce,从各个Map Task获取MOF文件。Reduce Task个数由客户端决定,Reduce Task 个数决定MOF文件分区数。因此Map Task输出的MOF文件都能找到对应的Reduce Task来处理...
大数据Mapreduce(1)编程实现文件合并和去重操作.docx

在Hadoop问世之前,其实已经...而Hadoop MapReduce的出现,使得大数据计算通用编程成为可能。我们只要遵循MapReduce编程模型编写业务处理逻辑代码,就可以运行在Hadoop分布式集群上,无需关心分布式计算是如何完成的。
MapReduce是一种编程模型,用于大规模数据集(特别是非结构化数据)的并行处理。这个模型的核心思想是将大数据处理任务分解为两个主要步骤:Map和Reduce。Map阶段:接受输入数据,并将其分解成一系列的键值对。...
大数据MapReduce和YARN架构原理.pdf
大数据MapReduce和YARN二次开发.pdf
MapReduce 编程模型只包含 Map 和 Reduce 两个过程,map 的主要输入是一对 值,经过 map 计算后输出一对 值;Hadoop 集群常驻进程,根据要处理的输入数据量,命令 TaskTracker生成相应数量的Map和Reduce进程任务,并...
专栏上一期我们聊到MapReduce编程模型将大数据计算过程切分为Map和Reduce两个阶段,先复习一下,在Map阶段为每个数据块分配一个Map计算任务,然后将所有map输出的Key进行合并,相同的Key及其对应的Value发送给同一个...

大数据mapreduce流程图
标签: 大数据

大数据MapReduce是什么
标签: 人工智能

大数据技术基础实验报告-MapReduce编程
1. MapReduce 介绍 MapReduce思想在生活中处处可见。或多或少都曾接触过这种思想。MapReduce的思 想核心是“分而治之”,适用于大量复杂的任务处理场景(大规模数据处理场景)。 Map负责“分”,即把复杂的任务分解...
林子雨大数据原理与技术第三版实验5实验报告 大数据技术与原理实验报告 MapReduce 初级编程实践 姓名: 实验环境: 操作系统:Linux(建议Ubuntu16.04); Hadoop版本:3.2.2; 实验内容与完成情况: (一)...

推荐文章
- Unity3D 导入资源_unity怎么导入压缩包-程序员宅基地
- jqgrid 服务器端验证,javascript – jqgrid服务器端错误消息/验证处理-程序员宅基地
- 白山头讲PV: 用calibre进行layout之间的比对-程序员宅基地
- java exit方法_Java:如何测试调用System.exit()的方法?-程序员宅基地
- 如何在金山云上部署高可用Oracle数据库服务_rman target sys/holyp#ssw0rd2024@gdcamspri auxilia-程序员宅基地
- Spring整合Activemq-程序员宅基地
- 语义分割入门的总结-程序员宅基地
- SpringBoot实践(三十五):JVM信息分析_怎样查看springboot项目的jvm状态-程序员宅基地
- 基于springboot+vue的戒毒所人员管理系统 毕业设计-附源码251514_戒毒所管理系统-程序员宅基地
- 【LeetCode】面试题57 - II. 和为s的连续正数序列_leet code 和为s的正数序列 java-程序员宅基地